性能分析器
要设置性能分析器的全局首选项,请转到 首选项 > 分析器 > CPU 使用率。
要为特定的运行配置设置首选项,请转到 项目 > 运行,然后选中 性能分析器设置 旁边的 详细信息。
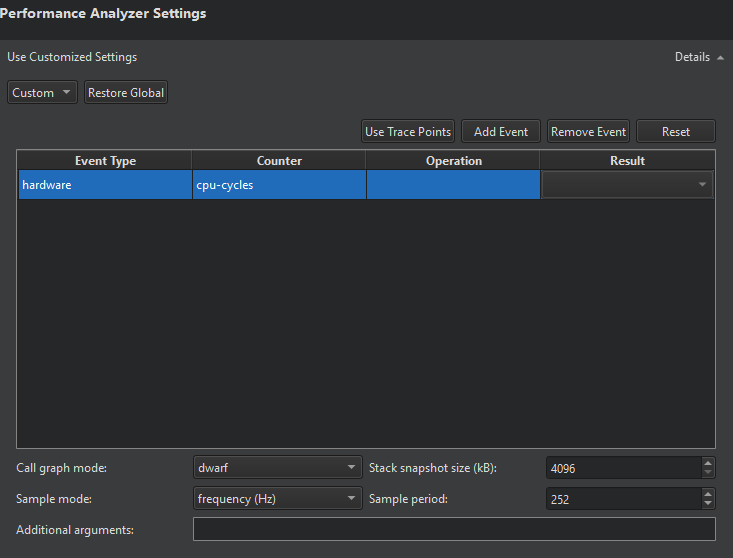
要编辑当前运行配置的设置,请选择性能分析器工具栏上  旁边的下拉菜单。
旁边的下拉菜单。

选择事件类型
事件表列出了触发性能分析器进行取样的事件。分析 CPU 使用率的最常见方式是通过周期性采样,由硬件性能计数器驱动,其对执行的指令或 CPU 循环的数量做出反应。您还可以选择使用 CPU 时钟的软件计数器。
选择 添加事件 将事件添加到表格。在 事件类型 中,选择要采样的事件的一般类型,最常见的为 硬件 或 软件。在 计数器 中,选择采样计数器。例如,硬件组中的 指令 或软件组中的 cpu-clock。
更专业的采样,例如通过缓存未命中或缓存命中,是可能的。但是,这取决于 CPU 的特定功能。对于这些专业事件,在 操作 和 结果 中提供更详细的采样指令。例如,选择在读取操作中对 L1-dcache 进行 未命中 的 缓存 事件,以采样 L1-dcache 未命中。
选择 移除事件,从表中删除所选事件。
选择使用跟踪点以替代当前选择的事件,并将采样模式设置为事件计数,将采样周期设置为码1。如果创建跟踪点在目标上定义了跟踪点,性能分析器将自动使用它们来分析内存使用情况。
选择重置将恢复事件、采样模式和采样周期的默认值。
选择采样模式和周期
在采样模式和采样周期中,指定如何触发样本
- 按事件计数采样指示内核每发生一次选中事件就采样
n次,其中n在采样周期中设置。 - 按频率(Hz)采样指令内核每秒钟尝试采样
n次,通过自动调整采样周期。在采样周期中设置n。
高频率或低事件计数会产生更准确的数据,但这会以更高的开销和更大量的数据生成为代价。实际的采样周期由目标设备上的Linux内核决定,它将Perf设置的周期仅视为建议。您请求的采样周期和实际结果之间可能存在重大差异。
通常,如果您将性能分析器配置为收集比可以通过目标设备和主机设备之间的连接传输的数据更多的数据,则在Perf尝试发送数据时,应用程序可能会被阻塞,处理延迟可能会急剧增加。您应然后更改采样周期或堆栈快照大小的值。
选择调用图模式
在调用图模式中,您可以指定性能分析器如何从您的应用程序中恢复调用链
- 帧指针或
fp模式依赖于提供的帧指针在分析中的应用程序中,并将指示目标设备上的内核遍历帧指针链以获取每个样本的调用链。 - Dwarf模式在没有帧指针的情况下也可以工作,但它会产生大量的数据。在每次触发样本时,它都会对当前的应用程序堆栈进行快照并将该快照传输到主机计算机进行分析。
- 最后分支记录模式不使用内存缓冲区。每次执行停止时,它会自动解码最后16个取分支。它仅支持最近的Intel CPU。
Qt和大多数系统库默认情况下都是不带帧指针编译的,因此帧指针模式仅对定制系统有用。
设置堆栈快照大小
性能分析器分析和Perf在Dwarf模式下生成的堆栈快照。在堆栈快照大小中设置堆栈快照的大小。较大的堆栈快照会产生更大的数据量来传输和处理。小的堆栈快照可能无法捕获高度递归的应用程序或其他大量堆栈使用的调用链。
为Perf添加命令行选项
在记录数据时将额外的命令行选项传递给Perf,请设置附加参数。设置--no-delay或--no-buffering以减少处理延迟。但是,这些选项并非所有版本的Perf都支持,如果传递了不受支持的选项,Perf可能无法启动。
解决JIT编译的JavaScript函数的名称
从版本5.6.0开始,Qt可以生成包含JavaScript函数信息的perf.map文件。性能分析器将读取它们并在时间轴、统计和火焰图视图中显示函数名称。这仅在正在分析的进程在主机计算机上运行时才起作用,而不是在目标设备上。要启用perf.map文件的生成,请将环境变量QV4_PROFILE_WRITE_PERF_MAP添加到运行环境并将其值设置为1。
分析收集的数据
时间轴视图显示了每个线程的CPU使用情况的图形表示和所有已记录事件的浓缩视图。
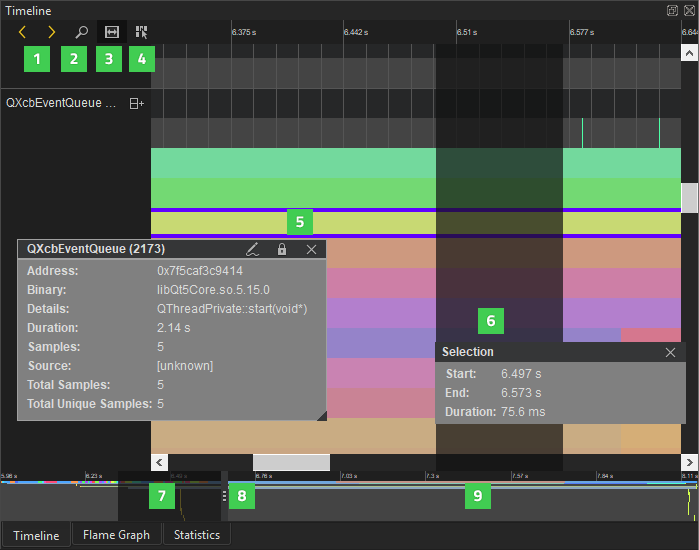
时间轴中的每个类别描述了应用程序中的一个线程。将光标移动到某一行的事件(5)上,以查看所需时间和在源代码中表示哪个函数。要仅在事件被选中时显示信息,请取消选中鼠标悬停时查看事件信息(4)。
轮廓(9)总结了收集数据的时间段。拖动缩放范围(7)或单击轮廓以在轮廓上移动。您还可以通过选择转到前一个事件和转到下一个事件(1)在事件之间移动。
选择显示缩放滑块按钮(2)以打开一个设置缩放级别的滑块。您还可以拖动缩放控件(8)。要重置默认缩放级别,右键单击时间轴以打开上下文菜单,并选择重置缩放。
选择事件范围
选择一个事件范围(6)以查看其表示的时间或放大到跟踪的特定区域。选择选择范围(3)以激活选择工具。然后单击时间轴以指定事件范围的开始。拖动选择柄以定义范围的结束。
使用事件范围也可用于测量两个后续事件之间的延迟。在第一个事件的结束和第二个事件的开始之间放置一个范围。持续时间显示事件之间的延迟(毫秒)。
要放大到事件范围,请双击它。
要删除事件范围,请关闭选择对话框。
理解数据
通常,时间轴视图中的事件指示函数调用所需的时间。将鼠标悬停在其上以查看详细信息。详细资料始终包括函数的地址、调用的大致持续时间、函数所在的ELF文件、此函数调用的活动收集的样本数量、函数在线程中遇到的次数和至少一次遇到此函数的样本数量。
对于具有调试信息的函数,详细信息包括源代码中的位置和函数名称。您可以通过单击此类事件将代码编辑器的光标移至与事件相关联的代码部分。
由于性能工具仅收集周期性样本,性能分析器无法确定函数被调用或返回的确切时间。然而,您可以在每个线程的第二行中精确地看到何时采集了样本。性能分析器假设如果相同功能在连续多个样本中的调用链中位于同一位置,则这代表了对相应功能的单个调用。当然,这是一种简化。另外,在采集样本之间可能存在其他被调用的功能,这些功能在配置文件数据中不会显示。但是,从统计学的角度来看,数据可能会最显著地显示花费最多CPU时间的功能。
如果在函数中没有遇到调试信息,则进一步检查堆栈可能会失败。对于采用汇编语言实现的一些符号, giải đóng包也会失败。如果在解封时失败,则只会显示调用链的一部分,周围的功能可能会看起来被中断。这并不一定意味着它们在应用程序执行过程中实际上被中断,而只是在解封失败的堆栈中找不到。
在JIT模式下运行的QML引擎中的JavaScript函数可以进行解封。但是,只有当QV4_PROFILE_WRITE_PERF_MAP设置时,它们的名称才会显示。由Qt Quick Compiler生成的编译JavaScript也可以进行解封。在这种情况下,编译器为JavaScript函数显示由编译器生成的C++名称,而不是它们的JavaScript名称。以解释模式运行时,涉及QML的堆栈帧也可以进行解封,显示解释器本身,而不是被解释的JavaScript。
调用链中包含的内核功能显示在每个线程的第三行。
事件的颜色表示具体线程在实际样本率下的实际样本率,在其持续期间。Linux内核只有在线程处于活动状态时才会对线程进行采样。同时,内核试图遵守请求的事件周期。因此,不同线程之间的采样频率差异表明,采样量更多的线程更有可能是整体瓶颈,而采样量较少的线程很可能已经花费时间等待外部事件,如I/O或互斥锁。
查看统计信息
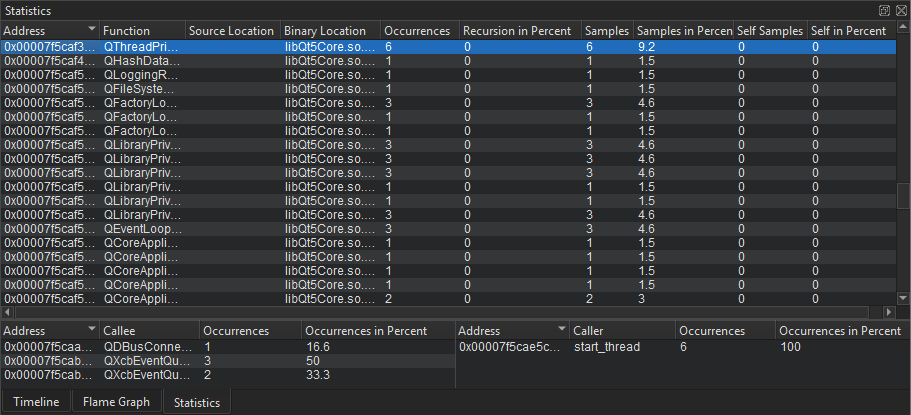
统计信息视图显示时间轴中每个函数的总样本数和在堆栈顶部(称为自我)时的样本数。这允许您检查需要优化的函数。发生次数多可能表明函数被不必要地触发或执行时间非常长。
单击一行可以移动到代码编辑器中源代码中相应的函数。
调用者和被调用者选项卡显示函数之间的依赖关系。它们允许您检查应用程序的内部函数。《b translate="no">调用者选项卡总结在主视图中调用的函数。《b translate="no">被调用者选项卡总结从主视图中选择的函数中调用的函数。
单击一行可以将代码编辑器中源代码中相应的函数移动到并选择它。
要将视图或行的内容复制到剪贴板,请在快捷菜单中选择复制表格或复制行。
将统计信息可视化成火焰图
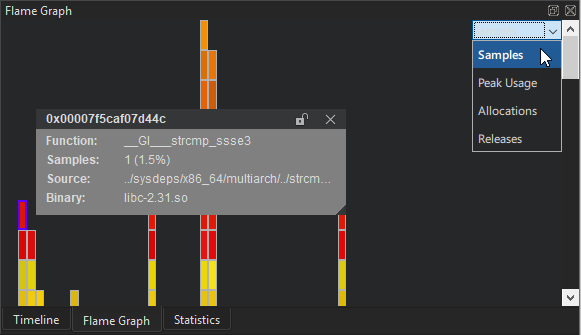
火焰图视图显示了执行情况的更简洁的统计概述。水平条形图显示了针对特定函数所采取样本的一个方面,相对于所有样本整体同一方面的相对情况。嵌套显示了哪些函数被哪些其他函数调用。
可视化按钮让您选择要在火焰图中显示的方面。
- 样本是默认的可视化。水平条的尺寸表示记录给定函数的样本数量。
- 在峰值使用模式下,水平条的尺寸表示相应函数在分配内存使用量达到峰值时的内存分配量。
- 在分配模式下,水平条的尺寸表示由相应函数触发的内存分配数量。
- 在释放模式下,水平条的尺寸表示由相应函数触发的内存释放数量。
峰值使用,分配和释放模式只有在记录了内存跟踪点的样本时才会显示任何数据。
视图之间的交互
当你在时间线,火焰图或统计中的任何一个视图中选择一个调用栈帧时,关于它的信息会在其他两个视图中显示。要在统计和火焰图视图中查看一个时间范围,请选择分析 > 性能分析器选项 > 限于时间线选定的范围。要显示完全的调用栈帧,请选择显示全范围。
加载数据文件
您可以使用Linux Perf工具的最新版本生成的任何perf.data文件,并在Qt Creator中查看它们。选择分析 > 性能分析器选项 > 加载perf.data文件来加载文件。
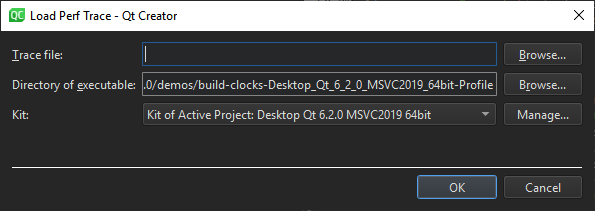
性能分析器需要知道记录数据时所处的上下文以找到调试符号。因此,您必须指定用于构建应用程序的套件和应用程序可执行文件所在的文件夹。
通过调用perf record来生成Perf数据文件。请确保使用带有--call-graph选项的Perf生成调用图。同时请确保,性能分析器可以使用在标准位置(/usr/lib/debug或二进制文件旁边)或作为您使用的Qt包的一部分可用的必要调试符号。
性能分析器可以读取以帧指针或dwarf模式生成的Perf数据文件。然而,要正确生成文件,必须满足许多先决条件。所有受支持的嵌入式平台系统图像都正确设置用于dwarf模式下的分析。对于其他设备,请检查Perf是否可以通过检查perf report或perf script为记录的Perf数据文件输出的方式合理地读取其自身数据。
加载和保存跟踪文件
您可以通过“分析”>“性能分析器选项”中的相应条目以性能分析器特有的格式保存和加载跟踪数据。此格式是自包含的,因此加载它不需要您指定记录环境。您可以无需任何工具链或调试符号,将此类跟踪文件传输到不同的计算机上,并在那里进行分析。
故障排除
以下原因可能导致性能分析器无法记录数据
- 您的系统可能全局禁用了Perf事件。预配置的Boo to Qt镜像带有启用的Perf事件。对于自定义配置,您需要确保文件
/proc/sys/kernel/perf_event_paranoid中的值小于2。为了在记录跟踪方面具有最大灵活性,您可以将其设置为-1。这允许任何用户记录任何类型的跟踪,即使使用原始内核跟踪点。启用Perf事件的方式取决于您的Linux发行版。在某些发行版中,您可以使用以下命令以root(或等效)权限运行
echo -e "kernel.perf_event_paranoid=-1\nkernel.kptr_restrict=0" | sudo tee /etc/sysctl.d/10-perf.conf
- 目标设备和主机之间的连接可能不足以传输Perf产生的数据。尝试修改堆栈快照大小或样本周期设置的值。
- Perf可能永远缓冲数据,而不会发送它。将
--no-delay或--no-buffering添加到附加参数。 - 某些版本的Perf在未给一定最小采样频率的情况下不会启动记录。尝试将样本周期设置为1000。
- 在某些设备上,特别是各种i.MX6板,硬件性能计数器无效,Linux内核可能在一段时间后随机失败记录数据。Perf可以使用不同类型的事件来触发样本。您可以通过在设备上运行
perf list获取可用事件类型的列表,然后在设置中选择相应的事件类型。事件类型的选择会影响采样的性能和稳定性。cpu-clocksoftware事件是一个安全但相对较慢的选择,因为它不使用硬件性能计数器,而是从软件驱动采样。在采样失败后,重启设备。内核可能已禁用了性能计数器系统的关键部分。 - Perf可能未安装。安装方式取决于您的Linux发行版。例如,尝试以下命令
- 在Ubuntu 22.04上:
sudo apt install linux-tools-$(uname -r) - 在Debian上:
apt install linux-perf
- 在Ubuntu 22.04上:
常规消息视图显示数据处理辅助程序输出的输出。
应用程序输出视图即使性能分析器显示错误消息,也会显示某些信息。
©2024芬兰Qt公司有限公司。本文档中包含的文档贡献是各自所有者的版权。本文档根据自由软件基金会发布的GNU自由文档许可证版本1.3的条款提供。Qt及其相关标志是芬兰及/或全球其他国家的Qt公司有限公司的商标。所有其他商标均为各自所有者的财产。
