使用 CoverageBrowser
使用通配符或正则表达式进行过滤
CoverageBrowser 提供了一种通用的使用通配符或正则表达式进行过滤的行列过滤机制。默认激活通配符表达式,而正则表达式则是当表达式以等号(=)开头时选中。点击过滤器图标可以将表达式从通配符转换为正则表达式,反之亦然。
| 图标 | 描述 |
|---|---|
 | 过滤器使用正则表达式语法。 |
 | 过滤器使用通配符语法。 |
 | 语法错误。更多详情显示在状态栏中。 |
通配符表达式
| 元素 | 含义 |
|---|---|
* | 任意字符(0个或更多) |
? | 任意字符 |
[...] | 一组字符 |
例如,foo*bar 匹配包含字符串 foo 后跟 bar 的任何测试。
正则表达式
正则表达式必须使用等号(=)作为第一个字符来激活。
模式匹配
| 元素 | 含义 |
|---|---|
c | 任何字符代表自己,除非它有特殊的正则表达式含义。因此 c 匹配字符 c。 |
\c | 紧跟在反斜杠后的字符匹配其自身,除非作了以下说明。例如,为了匹配字符串开头的字面量 caret,可以写 \^。 |
\a | 匹配 ASCII bell 字符(BEL,0x07)。 |
\f | 匹配 ASCII form feed 字符(FF,0x0C)。 |
\n | 匹配 ASCII 行尾字符(LF,0x0A,Unix 行尾)。 |
\r | 匹配 ASCII carraige return 字符(CR,0x0D)。 |
\t | 匹配 ASCII horizontal tab 字符(HT,0x09)。 |
\v | 匹配 ASCII vertical tab 字符(VT,0x0B)。 |
\xhhhh | 匹配与十六进制数 hhhh 相应的 Unicode 字符(介于 0x0000 和 0xFFFF 之间)。 |
\0ooo(即零 ooo) | 匹配八进制数ooo(介于0至0377之间)对应的ASCII/Latin1字符。 |
.(点号) | 匹配任何字符(包括换行符)。 |
\d | 匹配一个数字。 |
\D | 匹配一个非数字。 |
\s | 匹配一个空白符。 |
\S | 匹配一个非空白符。 |
\w | 匹配一个单词字符。 |
\W | 匹配一个非单词字符。 |
^ | 如果取反符(caret)作为第一个字符出现,表示取反集合字符,即紧跟在开方括号之后。例如,[abc] 匹配 a 或 b 或 c,但 [^abc] 匹配除了 a 或 b 或 c 以外的任何字符。 |
- | 破折号用于指示字符范围,例如 [W-Z] 匹配 W 或 X 或 Y 或 Z。 |
E? | 匹配0次或1次出现的 E。这个量词意味着 前面的表达式是可选的,因为它会在表达式出现在字符串中时匹配,无论表达式是否出现。它与 E{0,1} 相同。例如,dents? 将匹配 dent 和 dents。 |
E+ | 匹配1次或更多出现的 E。这与 E{1,} 相同。例如,0+ 将匹配 0、00、000 以及更多。 |
E* | 匹配0次或更多出现的 E。这与 E{0,} 相同。* 量词经常被误用。因为它匹配0次或更多出现,它将匹配根本不出现。例如,尝试使用正则表达式 \s*$ 来匹配以空白符结尾的字符串会给每个字符串匹配。该表达式找到零个或多个空白符后跟字符串的结尾,因此不以空白符结尾的字符串也会匹配。在这种情况下,我们需要的正则表达式是 \s+$ 以匹配至少有一个空白符在结尾的字符串。 |
E{n} | 匹配精确的 n 次出现的表达式。这与重复表达式 n 次相同。例如,x{5} 与 xxxxx 相同。它也与 E{n,n} 相同,例如 x{5,5}。 |
E{n,} | 匹配至少 n 次出现的表达式。 |
E{,m} | 匹配最多 m 次出现的表达式。这与 E{0,m} 相同。 |
E{n,m} | 匹配至少 n 次出现的表达式和至多 m 次出现的表达式。 |
() | 将表达式分组到子表达式中。 |
| | 选择(替代)。例如,aaa|bbb 匹配字符串 aaa 或 bbb。 |
字符串替换
| 元素 | 含义 |
|---|---|
& | 匹配的表达式 |
\n | 子表达式编号 n。例如,正则表达式 (.*):([0-9]*) 会匹配字符串 joe:18。替换字符串 \1 is \2 将产生以下结果:joe is 18。 |
代码/测试覆盖率级别
菜单项 Instrumentation > Level:x 设置目标代码覆盖率计数或(如果编译带有 instrumentation hit 支持),则设置目标测试覆盖率计数。
级别决定了要执行/测试覆盖率运行次数以判定经过仪器化的代码是否执行。例如,将级别设置为10,在代码覆盖率计数编译下,将需要执行源代码的每一行10次。如果使用代码覆盖率命中编译,则需要执行10次源代码的每一行。
菜单项工具 > 测试覆盖率计数模式和按钮 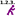 在代码覆盖率计数和测试覆盖率计数分析之间切换。这提供了当项目编译支持代码覆盖率计数时的代码覆盖率命中分析行为。
在代码覆盖率计数和测试覆盖率计数分析之间切换。这提供了当项目编译支持代码覆盖率计数时的代码覆盖率命中分析行为。
注意:要编译支持代码覆盖率计数的项目,请使用--cs-count命令行选项CoverageScanner。要编译支持仪器化命中的项目,请使用--cs-hit。
代码覆盖率算法
CoverageBrowser显示由CoverageScanner生成的代码覆盖率分析(语句块、决策或条件)。但是仪器化 > 覆盖率方法 > 语句块允许将分析减少到语句块的代码覆盖率。这与使用CoverageScanner的--cs-statement-block选项编译的结果相同。类似地,仪器化 > 覆盖率方法 > 决策展示了决策层的代码覆盖率分析。
以下表格总结了每种代码覆盖率分析方法所需的命令行选项
| 覆盖率分析 | CoverageScanner命令行选项 |
|---|---|
| 语句块 | --cs-statement-block |
| 使用完全仪器化的决策 | --cs-decision |
| 使用部分仪器化的决策 | --cs-decision --cs-partial-instrumentation |
| 使用完全仪器化的条件 | 默认 |
| 使用部分仪器化的条件 | --cs-partial-instrumentation |
优化执行顺序
CoverageBrowser可以计算测试的执行顺序,通过最小数量的测试达到最高的代码覆盖率。
在这个执行顺序中,覆盖率最高的测试首先执行。第二个测试是那个能让附加的代码覆盖率尽可能高的测试,以此类推。
这个功能适用于无法执行完整测试套件的情况,例如没有足够的时间或有大量手动测试。这使得您可以运行列表开头的多个测试,比如前20个,并快速获得高覆盖率。
要计算执行顺序,请按照以下步骤进行
- 在执行窗口中选择一组执行。
- 点击查看 > 优化执行顺序。打开优化执行顺序窗口
- 点击计算按钮开始分析。
错误定位
为了定位错误,CoverageBrowser模拟了人类程序员在源代码中寻找单个错误的行为。它将程序员的行为简化为从源代码行到源代码行的一个随机过程。在每一步之后,该过程都会尝试跳到下一个更好的错误候选者。在无限时间里,我们可以查看源代码行被选为失败最佳位置的概率。
程序指令之间存在强烈的依赖性,因此CoverageBrowser将始终一起执行的指令分组,因为它们不能从代码覆盖率数据中区分开来。错误定位算法与这些指令组一起工作,而不是与单个语句一起工作。
在过程开始时,随机选择一个被覆盖的源代码行。接下来,我们根据以下规则选择另一个仪器化的源代码行
- 选择一个覆盖当前行的测试。
- 然后按照以下方法选择下一行源代码:
- 如果测试通过了,导致失败的行不太可能是被所选测试执行的源代码行。因此,选择任何不属于此测试执行的插桩行。
- 如果测试失败了,选择任何被此测试执行的源代码行。
我们重复此过程,直到确定一组相关的源代码行。
错误位置示例
我们将用一个简单的示例来说明算法是如何工作的。以下函数计算一个数字的倒数
float inv( float x )
{
if ( x != 0 )
x = 1 * x ; // <- here is the bug
else
x = 0;
return x;
}错误本身很容易理解;使用乘法而不是除法。
我们的测试套件是
| 名称 | 测试 | 状态 |
|---|---|---|
| INV(0) | inv(0) == 0 | 通过 |
| INV(1) | inv(1) == 1 | 通过 |
| INV(2) | inv(2) == 0.5 | 失败 |
| INV(3) | inv(3) == 0.3333333 | 失败 |
| INV(4) | inv(4) == 0.25 | 失败 |
现在我们将逐步模拟错误定位算法。
注意:以下是用Coco使用的算法的简化版本。它将返回与实际算法相同的结果,但在实际使用中会非常慢。为了提高精确度和性能,《覆盖率浏览器》直接计算概率,而不使用以下采样方法。
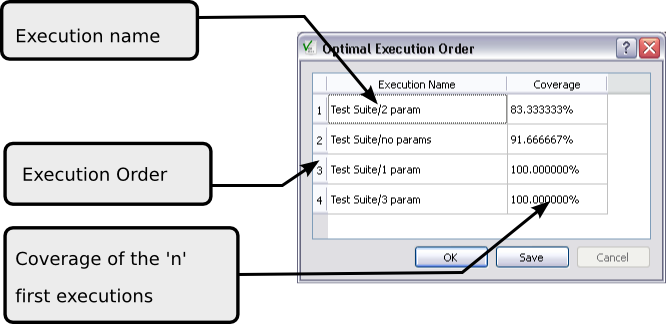
首先我们注意到,用测试无法区分以下两行if ( x != 0 )和return x;。如果这两行中的一行被执行,则另一行也会被执行。我们将它们组合在一起,作为一个单独的行来看待。这意味着如果我们估计这些行是良好的错误候选,我们无法确定哪一行包含错误。为了简化解释,我们省略了return;语句。
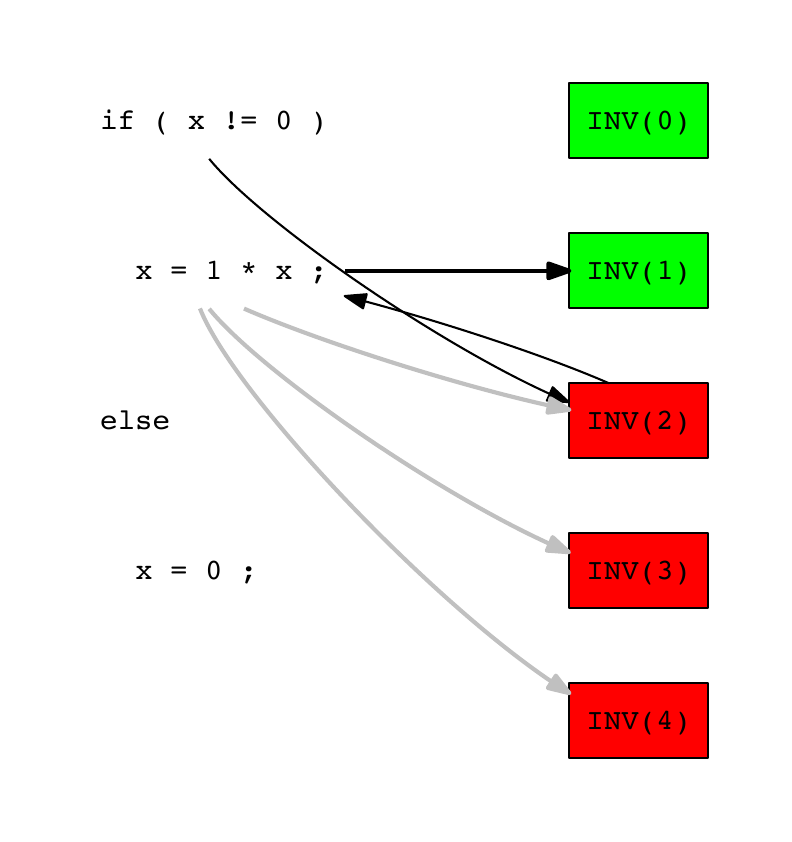
算法首先随机选择一行源代码作为错误候选。我们使用行if ( x != 0 )作为起点。然后算法在执行此行的测试列表中随机选择一个。假设它选择了INV(2)
INV示例错误位置 – 步骤1
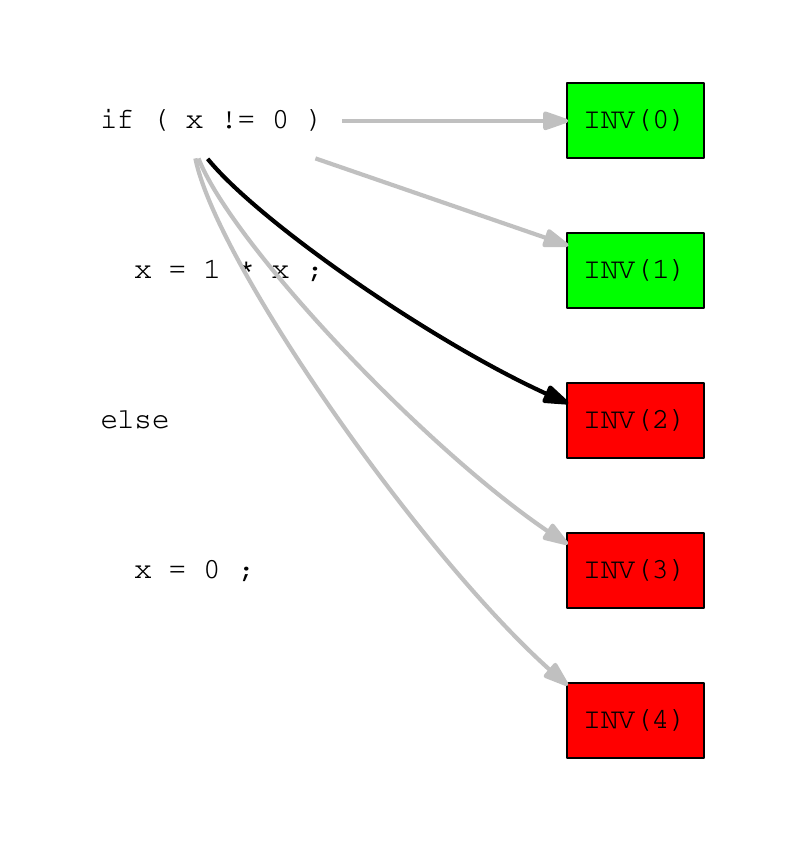
测试INV(2)已失败,我们假设负责错误的源代码行是由此测试执行的。然后算法选择另一个由INV(2)执行的行作为错误候选。我们假设是x = 1 * x
INV示例错误位置 – 步骤2
然后算法随机选择执行行x = 1 * x的测试集中的一个,即INV(1)、INV(2)、INV(3)和INV(4)。
INV示例错误位置 – 步骤3
测试INV(1)通过了,因此我们假设负责错误的源代码行是由此测试未执行的。我们选择x = 0;作为下一个候选
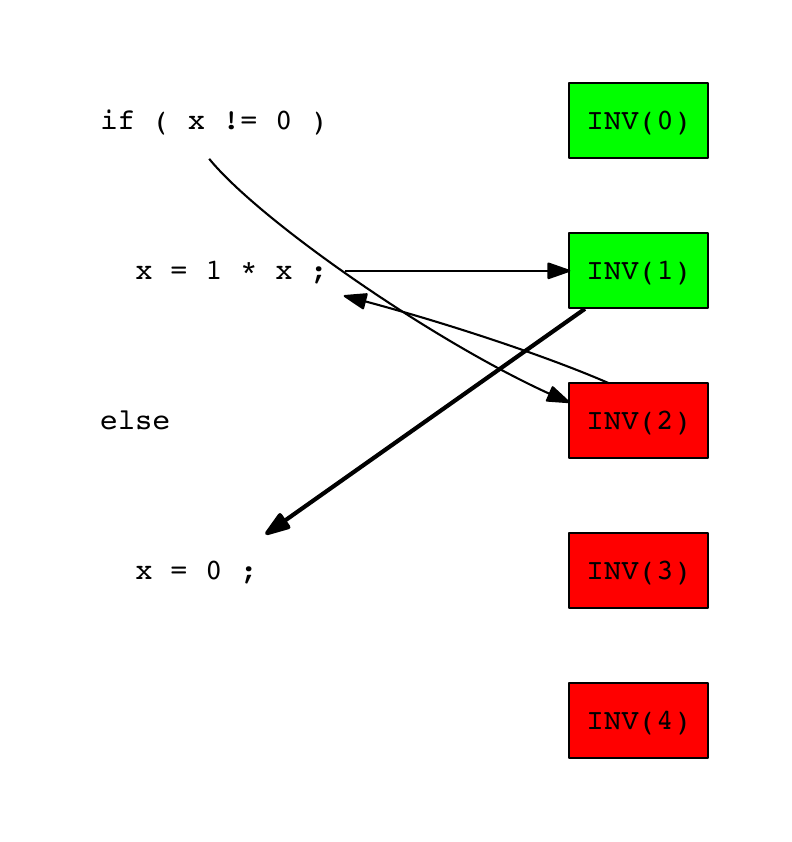
INV示例错误位置 – 步骤4
我们无限期地迭代此过程,并计算被选为错误候选的源代码行的概率
| 行 | 概率 |
|---|---|
x = 1 * x | 0.528 |
if ( x != 0 ) | 0.283 |
x = 0; | 0.188 |
出乎意料的是,行x = 1 * x出现错误的概率最高。
用法
计算错误位置
- 在执行窗口中选择一组执行。至少有一组执行应该已失败。
- 单击查看 > 错误位置 打开 错误位置 窗口
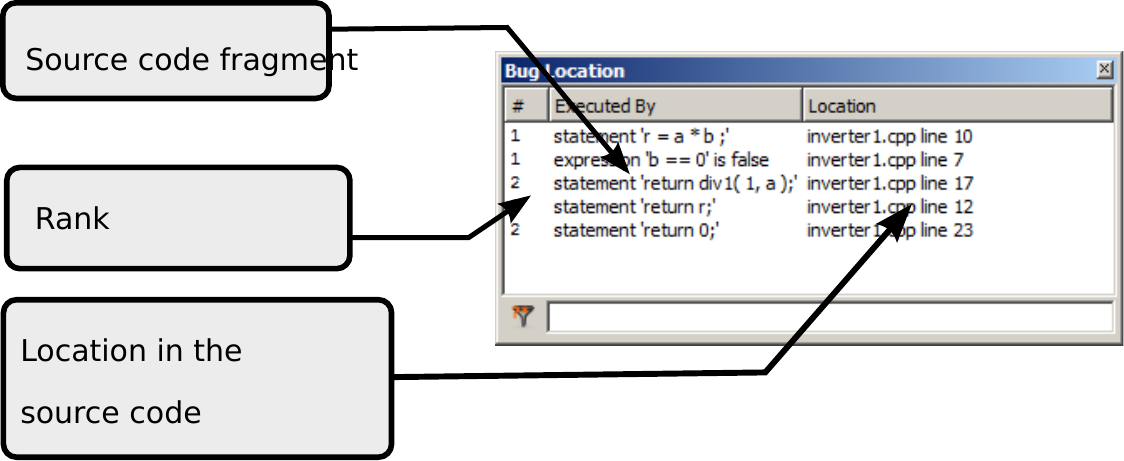
- 点击计算按钮开始分析。
补丁分析
选择 工具 > 补丁文件分析 以生成有关补丁对项目测试覆盖率影响的报告,而无需对修补版运行测试套件。
的前提是项目存在.csmes和.csexe 文件,并且已将这些文件载入 CoverageBrowser,以及一个 diff 文件。补丁分析在与自动测试程序工作效果最佳,这些程序以这种方式被仪器化,使得测试的名称为Coco所知(见测试套件与Coco)。行覆盖率(--cs-line)和语句块覆盖率(--cs-statement-block)不应禁用。默认情况下是开启的。
diff文件必须处于统一格式。它由Linux™的diff实用工具的-u选项生成,也是几个版本控制系统的默认输出格式(见diff文件的生成)。
单击 工具 > 补丁文件分析 以打开包含以下字段的补丁文件分析对话框
- 标题:报告的标题,适用于HTML和CSV。
- 补丁文件:包含项目更改的补丁文件的路径。
- 输出:输出文件及其类型
- 类型:HTML或Excel CSV格式。
类型字段右边的字段包含生成的报告文件的名称和路径。
- 源代码参数:对于HTML报告,标注源代码的显示
- 工具提示最大大小:HTML报告中标注的补丁文件有工具提示,该工具提示显示执行了特定行代码的测试。此参数设置工具提示中可以出现测试的最大数量。值为0时,不显示任何工具提示。
- CSV参数:CSV报告的格式
- 列分隔符:列分隔符号可以是逗号或分号。
- 部分:报告的内容
- 执行统计:创建一个将测试按其结果分组的表。它显示了通过、失败、需要手动测试以及执行状态未知测试的数量。
- 执行:创建受补丁影响执行的代码的测试列表。对于每个测试,显示名称和执行结果。
- 源代码统计:创建一个表,显示补丁对测试覆盖率的影响。它显示了补丁中的多少行被测试覆盖,多少行没有被覆盖,以及Coco无法确定是否被覆盖的行数。这些数字显示了删除、添加的行以及补丁中的所有行。
- 标注补丁源:创建补丁文件的标注版本。补丁中每行代码如果被删除则显示为红色,如果被添加则显示为绿色,否则为灰色。同时显示代码行的行号,包括应用补丁前后的行号,以及覆盖某行的测试数量。最后一个字段还具有工具提示,显示哪些测试覆盖了特定的行。工具提示只在工具提示最大大小设置为非零值时可见。
要生成报告,请单击确定或显示,这还会打开一个浏览器窗口以显示生成的报告。单击应用将保存对话框条目的值而不生成报告,而单击取消将关闭对话框而不保存任何内容。
比较两个软件版本的代码覆盖率
CoverageBrowser比较用于
- 检查修改的/未修改的代码是否被正确测试。
- 确定哪些测试受源代码修改的影响。
此功能特别适用于比较只包含少量修改(仅限错误修复)的两个版本,并仅对修改的代码进行测试。
在此模式下,CoverageBrowser使用以下表格总结的排版规则。在检测到相同的代码部分时,会忽略注释和空白。
| 规则 | 源代码窗口 | 方法列表 | 源代码列表 | 执行列表 |
|---|---|---|---|---|
| 正常字体 | 相同的源代码部分 | 相同的方法 | 相同的文件 | 两个版本中可用的执行 |
| 粗体 | 修改的方法 | 修改的文件 | ||
| 粗体+下划线 | 插入的新文本 | 新方法 | 新文件 | 新执行 |
| 粗体+删除线 | 删除的文本 | 删除的方法 | 删除的文件 | 缺失的执行 |
CoverageBrowser比较和差异算法特别用于类似于C的语言,如C、C++、C#和QML;它忽略了空白和注释中的修改。
参考数据库
参考数据库是用于比较的基线仪器数据库。要选择它,请单击工具 > 与...比较并选择一个.csmes数据库。要在工作数据库和参考数据库之间切换,请单击工具 > 切换数据库。
一旦加载了参考文件,执行、源和方法窗口中就有更多的过滤选项。这些过滤器可以让您显示/隐藏、修改、新增加、删除或相同的程序和源代码文件。
执行窗口显示参考版本和当前版本执行的混合体
- 带有线条的执行仅适用于参考版本。计算出的统计量对应于参考版本的覆盖率。此值可以解释为当这些测试在当前版本上重新执行时的预期代码覆盖率。
- 带有下划线的执行是新测试。
- 两个版本中都有的执行不突出显示。
修改 未修改源代码的覆盖率分析
CoverageBrowser能够将代码覆盖率分析限制为已修改的(相应地,未修改的)函数。当仅选择修改的(相应地,未修改的)函数的覆盖率分析时,CoverageBrowser将所有未修改的(相应地,已修改的)函数视为未进行仪器化。将代码覆盖率限制为修改的函数可以是一个实际的验证新功能已测试的方法,以及识别受修改影响的测试列表的方法。要将代码覆盖率限制为修改的函数(相应地,未修改的函数),请单击工具 > 修改函数分析(相应地,工具 > 相同函数分析)。
更改仪器数据库
合并仪器
点击 文件 > 与...合并 以导入来自其他 .csmes 文件的执行情况、源代码和 Instrumentations。注释和标记为已验证的代码将被合并。
导入单元测试
点击 文件 > 导入单元测试 将单元测试执行报告导入当前应用程序。只有出现在主应用程序中的源文件执行报告被导入。其他源文件的执行(例如测试代码)将被忽略。
导入审阅者注释
点击 文件 > 导入审阅者注释 以导入当前仪器数据库前版本的注释和手动验证。即使源代码已修改,未修改的函数的注释和手动验证也将被导入。
函数分析器
当在编译器和链接器的命令行参数中添加 --cs-function-profiler=option(带选项 all 或 skip-trivial)时,函数分析器将激活。它显示每个函数在 CoverageBrowser 中花费的时间。
就像代码覆盖率一样,分析器允许您分析每个选择的测试组中的每个过程的耗时。它还允许您比较两个产品版本或执行之间的时间。
分析信息在 函数分析器 窗口中显示
- 总时长:该函数的累积执行时间。
- 计数:函数调用次数。
- 平均时长:单次调用的平均执行时间。
所有时间信息均为所选执行。要从分析中交互式地排除或包含测试,请在 执行 窗口中选择它们。单击列标题可排序列,这样更容易快速找到最高值。
注意:分析器使用的 tick 与用于计算应用程序执行时间的 tick 不同。前者可以测量短时间,但精度不一定绝对相同。因此,在分析器和执行窗口之间显示的计时可能会有所不同。
比较执行
在 CoverageBrowser 中,可以通过选择一组参考函数并与另一组比较来实现对两组测试之间的分析信息进行比较。原理很简单:选择一组参考函数并与另一组进行比较。
比较通过一个额外的列中的差异和比率来实现
- 差异:差异 (选定 - 参考) 允许您比较两组之间的绝对时间和计数。
- 比率:比率 (选定 / 参考) 允许您比较两组之间的相对差异。
对于函数分析器提供的所有三种测量值(计数、持续时间、平均持续时间),还提供了三个额外的列,其中包括参考集的值、差异和比率。通过排序这些列,您可以快速识别两个测试之间所用计算资源的差异。
比较两个软件版本
与比较二进制文件的执行方式完全一样,您还可以比较两个不同二进制文件的执行情况。这允许您分析两个软件版本性能的差异。
在 CoverageBrowser 中,它提供了与 分析器 窗口中进行执行比较相同的计算。它还提供了一些额外的列,可以查看从一个版本到另一个版本不同仪器化的函数。
Coco v7.2.0©2024 The Qt Company Ltd.
Qt 及相关标志是芬兰及/或其他国家 The Qt Company Ltd. 的商标。所有其他商标均为其各自所有者的财产。
