使用Coco测试引擎发现新的测试数据
Coco测试引擎是一组宏和命令行工具,可以一起生成函数的测试数据,同时尝试最大化代码覆盖率并最小化给定的数据集的测试行数。它重复执行由Coco测试引擎生成数据的单元测试,并使用Coco来衡量执行结果中的代码覆盖率。
本教程将向您展示如何编写使用Coco测试数据发现功能的数据驱动测试用例。在您执行此测试并处于发现模式后,我们将向您展示如何处理结果,稍后如何运行对发现的测试数据集的回归测试。
本教程展示了两种不同的代码集成方法。第一种方法使用Coco测试引擎驱动程序,也称为cocotestengine,它执行用户编写的目标程序。第二种方法使用第三方单元测试框架,CppUnit。
示例应用程序基于第简单示例部分中介绍的简单表达式解析器。建议您在继续之前,至少完成UNIX和macOS设置或Microsoft Windows设置教程部分的步骤。
我们希望测试的函数是Parser::parse(const std::string &)。下面是一个示例数据驱动测试,在获取数据行后调用parse(),并将结果与预期值进行比较。
// fetch a test data value into a variable called 'expression' COCOTEST_FETCH( std::string, expression ); Parser ps; // Parse the test data std::string result = ps.parse( expression ).msg(); // compare the result to the expected value COCOTEST_CHECK( result );
解析器示例的构建环境设置
为了正确工作,必须将SQUISHCOCO环境变量设置为Coco安装目录。在Windows上,这是由Coco安装程序为您完成的,但在Linux或macOS上必须手动设置。例如,
$ export SQUISHCOCO=$HOME/SquishCoco
这将用于定位位于Coco安装目录的include子目录中的头文件。
使用Coco测试引擎驱动程序生成测试数据
本章介绍如何使用Coco自带的驱动工具生成测试数据和执行测试。与CPPUnit方法相比,这种方法的优势在于还可以检测和恢复崩溃。
本例的文件在Windows上的位于《<Windows Coco>》\parser\parser_cocotestengine目录中,而在UNIX和macOS上位于SquishCoco/samples/parser/parser_cocotestengine。请确保在您的开发区域中使用这些目录的副本进行工作,而不是直接在安装目录上工作。有关为您的操作系统设置示例的指南,请参阅《UNIX和macOS设置》或《Microsoft Windows设置》。
创建目标程序
为了准备要发现测试数据的测试函数,必须编写一个调用该函数的目标程序。本例中的示例是testcases.cpp。
在源文件顶部必须包含CocoTestEngine.h。
#include "CocoTestEngine.h" #include "parser.h"
CocoTestEngine.h定义了用于目标编译的宏和函数。它在Windows上位于《<Windows Coco>》\include目录中,在UNIX和macOS上位于SquishCoco/include目录中。
给定一个我们希望生成数据的函数,我们可以使用COCOTEST()、COCOTEST_FETCH()和COCOTEST_CHECK()宏定义一个带有名称的测试用例。关于此的示例,请参阅COCOTEST()。'%COCOTEST()将代码块转换成可重复调用的函数,每次调用都会为测试数据的一行调用一次。
COCOTEST块开头有一组或多个COCOTEST_FETCH()语句,用于定义变量并将输入值赋给它们。在末尾,有一组或多个COCOTEST_CHECK()宏,它根据exec_mode是否为测试、发现或学习来比较、插入或更新期望的输出值。
COCOTEST( testname )
{
// declare a variable 'expression' and fetch a value into it:
COCOTEST_FETCH( std::string, expression ) ;
Parser ps;
// parse the input data, and capture the result in 'result'
const std::string result = ps.parse( expression ).msg();
// compare 'result' to an expected value from the data row.
COCOTEST_CHECK( result ) ;
}在文件末尾,必须始终有一个COCOTEST_MAIN,它提供了一个main()函数。
COCOTEST_MAIN
编译目标程序
现在必须编译和纪实目标程序。这意味着编译器的包含路径必须配置成可以找到文件CocoTestEngine.h。对于纪实,我们使用前面版本的instrumented脚本,这次在parser/parser_cocotestengine中。
在Linux上
$ ./instrumented make -f gmake.mak tests
在Windows上
> instrumented.bat nmake -f nmake.mak tests
这将构建一个名为testcases(.exe)的目标程序。目标程序的目标也运行测试用例,执行回归测试。
COVERAGESCANNER_ARGS(如--cs-mcdc或--cs-mcc)是可选的,但会增加更多覆盖点,从而改善代码覆盖率分析。--cs-function-profiler在此示例中也不必要求。但是,有一个新选项是必需的,以确保发现能够正常工作:--cs-test-case-generation。
我们已将这些推荐选项添加到COVERAGESCANNER_ARGS中,以排除部分目标代码
--cs-exclude-path=../../cppunit-1.15.1 --cs-exclude-file-abs-wildcard=*\unittests.cpp
使用这些,搜索算法仅使用从测试函数开始的覆盖率数据。
发现测试数据
配置文件
JSON格式的文件用于存储配置选项和测试数据。它们需要位于当前工作目录中,以便由cocotestengine找到,除非通过传递一个-d 目录参数给它。
每个文件都与一个测试相关联,格式为<测试名称>.<文件类型>.json。字段<测试名称>是测试的名称,必须与传递给COCOTEST()宏的参数匹配。
字段<文件类型>可以是以下之一
- 用于测试数据生成器的配置的
cfg - 用于测试数据(如果不存在,则在
--discover过程中创建的)的data - 用于运行时参数的
run(在使用cocotestengine时不需要)
配置文件包含不同输入值的生成器以及预期输出值的列表。它具有扩展名.cfg.json,需要顶层键为"inputs"和"outputs"。"inputs"字段包含输入变量的名称。在每个变量名下面是一个特定的变量的"generator"。然后是生成器所需的属性及其值。生成器确定变量的数据类型和输入变量可能包含的分布、范围或模式。《code translate="no"><outputs>字段是预期输出变量名称的数组。
例如,可以在parser_v5和parser_cocotestengine子目录中找到的文件testname.cfg.json。
{
"inputs": {
"expression": {
"generator": "RegExpString",
"meanLength": 10,
"pattern": "(abs|sign|sqrt|log10|a?tan|a?sin|a?cos|factorial|ln|log|exp|[-+/=<>^|!*%0-9A-Z.()]+)*"
}
},
"outputs": [
"result"
]
}它包含名为"expression"的输入变量,它具有"RegExpString"或正则表达式生成器。属性"meanLength"定义"*"和"+"操作符的平均长度,而"pattern"包含所有生成字符串必须遵循的匹配模式。例如,此生成器可以生成类似于"3*2"或"sqrtabs123"的字符串。
开始测试数据发现
现在我们有了配置文件,我们可以使用cocotestengine驱动程序来--discover一些测试数据。Makefile中的每个文件都有一个discover目标,该目标运行100000次尝试。要执行此目标
在Linux上
$ ./instrumented make -f gmake.mak discover
在Windows上
> instrumented.bat nmake -f nmake.mak discover
调用可能如下所示
cocotestengine -e ./testcases -d . -t testname --discover --max-tries=100000 --update=2
-e testcases定义解析器可执行文件的路径。在Windows上,可执行文件将以.exe结尾。-d .定义包含配置和数据文件的目录。-t testname设置测试名称。然后从目录和测试名称组合文件的名称:因此数据文件名为./testname.data.json。--discover启用发现模式。--max-tries=100000设置驱动程序生成的测试行数。默认值是10000。- 《code translate="no">--update=2虽然不是严格必要,但很有用:使用它,
cocotestengine每2秒钟就打印一次发现过程的状态更新。
运行它,您可能会看到如下所示的输出
Generating data for test "testname" (100000 tries). 10:55:54 Found 66 rows in 24700 tries. Coverage=76.87% (309/402). 10:55:56 Found 67 rows in 49700 tries. Coverage=78.11% (314/402). 10:55:58 Found 69 rows in 75000 tries. Coverage=78.86% (317/402). 10:56:00 Found 71 rows in 100000 tries. Coverage=80.35% (323/402).
经过100000次尝试后,我们实现了80%的代码覆盖率,而且我们只用了71行,在约7秒钟的执行时间内就找到了它们。
最终,所有找到的数据行将写入到testname.data.json。如果发现过程花费太多时间,请按Ctrl-C;然后发现停止,目前发现的所有数据将写入磁盘。
与生成数据一起工作
测试数据文件
该数据文件包含特定测试的可能输入值和预期输出值。如果尚未创建,Discover步骤会为您创建它。它具有扩展名.data.json,包含一个可选的对象字段"types"和一个必需的数组字段称为"data"。"types"包含输入和输出字段名称及其数据类型,可以是以下之一
"Bool""Integer""UnsignedInteger""Float""String"
"data"是一个包含测试数据rows的数组,具有字段"inputs"和"outputs",包含"variableName":"value"对。每行还可能包含可选字段validated,表示已手动检查预期输出值的正确性,以及"crash",表示此行的输入在测试发现期间引发了崩溃。
例如,文件testname.data.json可以在parser_v5和parser_cocotestengine子目录中找到。
{
"data": [
{
"inputs": {
"expression": "3+2"
},
"outputs": {
"result": "Ans = 5"
},
"validated": true
},
{
"inputs": {
"expression": "cos(0)"
},
"outputs": {
"result": "Ans = 1"
},
"validated": true
},
{
"inputs": {
"expression": "sqrt(9)+tan(2)"
},
"outputs": {
"result": "Ans = 0.81496"
},
"validated": true
}
]
}发现运行完成后,我们可以使用文本编辑器或在更好的表格中使用testdataeditor查看testname.data.json中的所有行。注意下面的图片中,发现的行尚未验证,而前3行已验证。
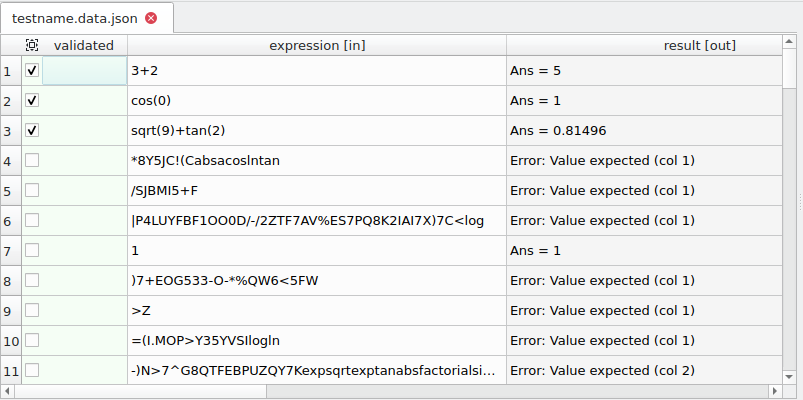
测试数据编辑器
由于数据文件存储为JSON格式,因此可以使用任何文本编辑器创建和修改它们。为了方便起见,Coco包括一个Test Data Editor工具,该工具允许以表格形式查看和编辑数据文件。名为testdataeditor的可执行文件可以在Coco二进制目录中找到。它接受一个目录或要打开的数据文件列表作为参数。
要编辑样本目录中的数据文件
$ testdataeditor testname.data.json
主窗口包含一个文件系统面板,便于打开和切换测试数据文件,以及一个列面板,显示每列的类型信息,此信息可来自数据文件的"types"字段或从"data"的内容中推断而来。
中心表的表视图显示数据文件的内容。第一列是validated。如果数据文件中有,可以随后是crashed。接下来是由[in]指示的输入变量,以及由[out]指示的输出变量。
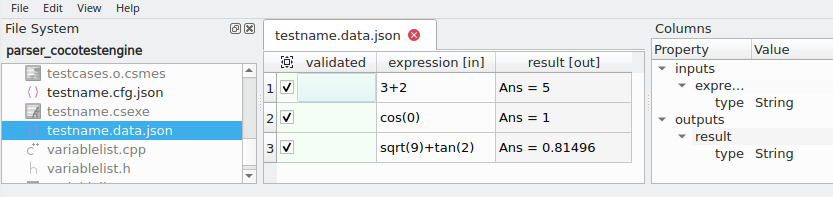
编辑菜单包含编辑表格的常见命令,例如添加和删除行和列。
分析覆盖率
现在应该可以在CoverageBrowser中打开testcases.csmes并加载/删除testcases.csexe执行报告。在Windows上,这些文件分别命名为testcases.exe.csmes和testcases.exe.csexe。
在Linux上
$ coveragebrowser -m testcases.csmes -e testcases.csexe
在Windows上
> coveragebrowser -m testcases.exe.csmes -e testcases.exe.csexe
在执行窗口中,有树节点用于您的数据驱动测试。展开它们以找到testname。请注意,此树节点有子节点,每个测试数据行一个。
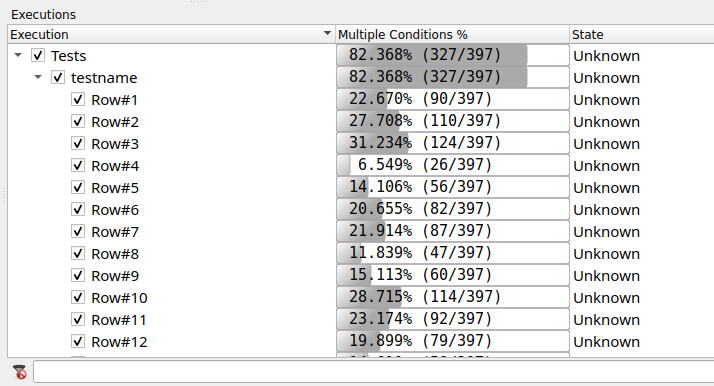
从覆盖率浏览器,您可以打开parser.cpp,看看是否有一些可以通过添加一或两行数据轻松覆盖的不受覆盖的情况。在运行我们的发现数据集之后,然后打开覆盖率浏览器到该文件,将看到如下内容
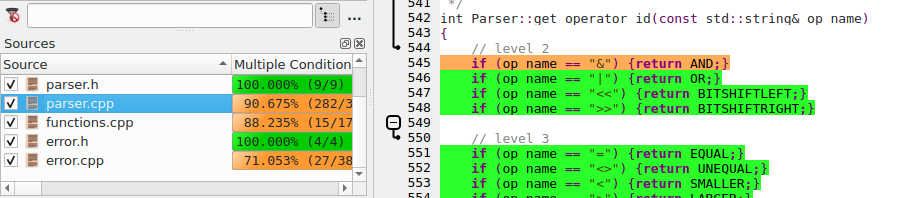
对get_operator_id()函数的覆盖率快速浏览显示,反斜杠运算符(&)没有被覆盖,所以任何使用该运算符的测试数据行都将增加总体覆盖率。
- 注意覆盖率浏览器中的当前覆盖率%(总和或仅限于
parser.cpp)。我们想要提高它。
验证测试数据行
再次在testdataeditor中打开testname.data.json。
机器生成数据后对其进行整理非常重要。这是我们检查有趣数据行预期值并获得可能的非有趣行删除的步骤(虽然请记住,不管测试数据看起来多愚蠢,它确实覆盖了其他测试行没有覆盖的东西)。
每行数据都有一个可选属性:validated,可以在testdataeditor中进行勾选或取消勾选。当一行被验证时,这意味着
- 预期值是“正确”[*]
- 在随后的发现运行中该行不会被删除。
[*]如果预期值稍后通过运行带有--learn的cocotestengine后更新,则validated变为false。
添加一些新行以增加覆盖率
- 通过
testdataeditor中的编辑 - 插入行添加1或2行数据,其中输入是使用(&)运算符的表达式(或您之前覆盖率报告中留下的任何其他未被覆盖的运算符)。 - 为了获得相应的输出,以学习模式执行测试
cocotestengine -e ./testcases -d . -t testname --learn
这将在数据文件中将预期输出参数更新为实际的函数输出。它还将生成一个新的包含更新覆盖率的{testcases.csexe}文件。
- 再次用
testdataeditor打开数据文件。您刚刚手动插入的行现在应该有相应的输出。然后您可以验证这些行。
运行数据驱动的回归测试
现在我们已经检查并验证了一些生成数据,我们准备将其用于数据驱动的回归测试。如果目录中存在,请确保删除testcases.csexe。然后,执行此命令
$ cocotestengine -e ./testcases -d . -t testname Running test "testname" (73 rows). Rows run: 73. Passed: 73, Failed: 0.
所有测试都通过了,因为这是经过配置的,我们将有一个包含此类测试覆盖率的testcases.csexe文件。
重新查看覆盖率
现在应该能够打开覆盖率浏览器中的testcases.csmes并再次加载/删除testcases.csexe执行报告。
在覆盖率浏览器中,您可以再次打开parser.cpp。看看是否已覆盖缺失的运算符。
- 检查整体覆盖率%是否有所增加。
在我们这个例子中,在添加一行数据后,覆盖率从82%增加到86%。
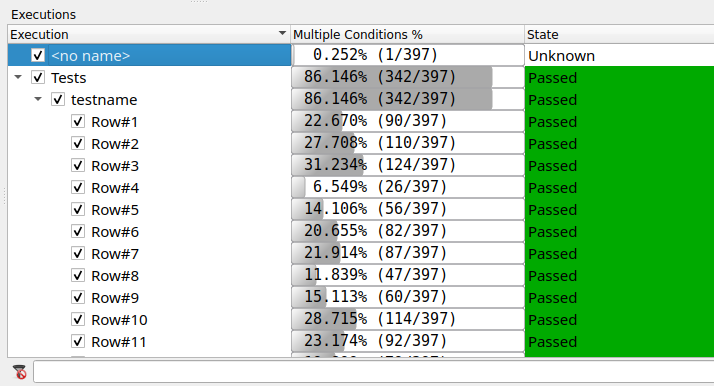
现在执行也有一个执行状态,用于标识测试行是否已通过或失败,以及该行是否经过验证。
将测试数据发现与CPPUnit集成
本节介绍了如何将测试数据发现集成到单元测试框架CPPUnit中。在此方法中,测试发现和测试执行是由单元测试框架驱动的,而不是通过 cocotestengine 。有关与其他单元测试框架集成的信息,请参阅与第三方单元测试框架的集成。
此示例基于为简单表达式解析器编写的测试。该示例的文件可以在Windows上的<Windows Coco>\parser\parser_v5目录中找到,在UNIX和macOS上为SquishCoco/samples/parser/parser_v5。请确保在您的工作空间中对这些目录的工作副本进行操作,而不是在安装程序上直接操作。有关为操作系统设置示例的指南,请参阅UNIX和macOS设置或Microsoft Windows设置。
适应性单元测试
为了将现有的CpuUnit编写的单元测试改为测试数据发现,必须采取以下步骤。
第一个改动是将CocoTestEngine_cppunit.h包含到单元测试源文件中
#include "CocoTestEngine_cppunit.h"该文件包含用于执行和发现测试的宏。它在Windows上的<Windows Coco>\include目录中,或UNIX和macOS上的SquishCoco/include。在不使用Squish Coco进行仪器化的情况下,也可以执行测试,但只有通过仪器化才能进行测试数据发现。
我们可以为Parser::parse函数添加一个新的单元测试。它提供一个字符串expression作为输入,并监控输出字符串result。
单元测试的代码在unittests.cpp中
void testDataDiscovery( void ) { COCOTEST_BEGIN( testname ) { COCOTEST_FETCH( std::string, expression ); Parser ps; std::string result = ps.parse( expression ).msg(); COCOTEST_CHECK( result ); } COCOTEST_END() }
该代码意味着在执行单元测试期间,从文件testname.data.json中的每行测试数据中提取字符串expression作为对parse()函数的输入,并将其与记录的值进行比较。COCOTEST_BEGIN()和COCOTEST_END()定义了一个循环,用于在测试数据行的每行上执行主体(COCOTEST块)。数据行从文件testname.data.json中依次通过COCOTEST_FETCH()提取到变量expression中。
我们通过使用COCOTEST_CHECK()宏,将每个字符串expression传递到parse()函数作为输入,并存储result,然后将其与我们的测试数据中的预期值进行比较。
配置文件
如前节所述,使用JSON格式的文件来存储配置选项。该文件testname.cfg.json在此之前提供,作为一个示例。它将用于根据正则表达式模式生成一个算术表达式的列表。
需要使用一个名为运行配置文件的不同的文件来提供执行参数。为此,有一个名为testname.run.json的文件。
{
"exec_mode": "Discovery",
"save_interval": 2,
"max_tries" : 100000
}第一个属性,指定 exec_mode,可以有3个可能的值:"Discovery"(用于发现测试数据),"Test"(用于执行测试)和 "Learn"(用于更新测试数据的预期值)。
此示例启用了最大尝试次数设置为100000的发现模式。它还会每2秒保存生成的数据文件。
开始测试数据的发现
一旦正确配置了文件 testname.run.json,只需执行单元测试即可。
在发现模式下,COCOTEST_CHECK() 将数据行保存到文件 testname.data.json 中。
在Windows上
$ instrumented.bat nmake -f nmake.mak tests
在Linux上
$ instrumented make -f gmake.mak tests
单元测试在构建结束时自动执行。其中有一个名为 testDataDiscovery 的测试具有 COCOTEST 块并执行数据驱动测试。
您应该看到以下输出
ParserTest::testInt : OK ParserTest::testInvalidNumber Failed test ParserTest::testInvalidNumber: equality assertion failed - Expected: Error: Syntax error in part "1.1e+" (col 4) - Actual : Ans = 1.1 : assertion [...] ParserTest::testDataDiscovery : OK
生成文件 testname.data.json 并可以查看和编辑,请使用 测试数据编辑器。
执行数据驱动回归测试
要执行单元测试,只需编辑 testname.run.json 并按如下方式更改执行模式。
"exec_mode": "Test"
如果不存在此文件,这也是默认设置。
在Windows上
$ instrumented.bat nmake -f nmake.mak tests
在Linux上
$ ./instrumented make -f gmake.mak tests
Coco v7.2.0©2024 Qt公司有限公司。
Qt及其相关标志是Qt公司有限公司在芬兰和其他国家/地区的商标。所有其他商标均为其各自所有者的财产。
